秒启动的基石,vite 依赖预构建的原理
vite 在开发环境能够做到秒启动的原因有两个
- No Bundle:即跳过打包,通过浏览器 ESModule 解析源文件
- 依赖预构建:将常用依赖提前编译和处理,从而在启动阶段大大减少了开销
依赖预构建不仅能实现 vite 的秒启动,还能够兼容 CommonJS 的依赖产物、合并 ESModule 多个模块,下面就展开讲讲 vite 依赖预构建的实现原理
实现原理
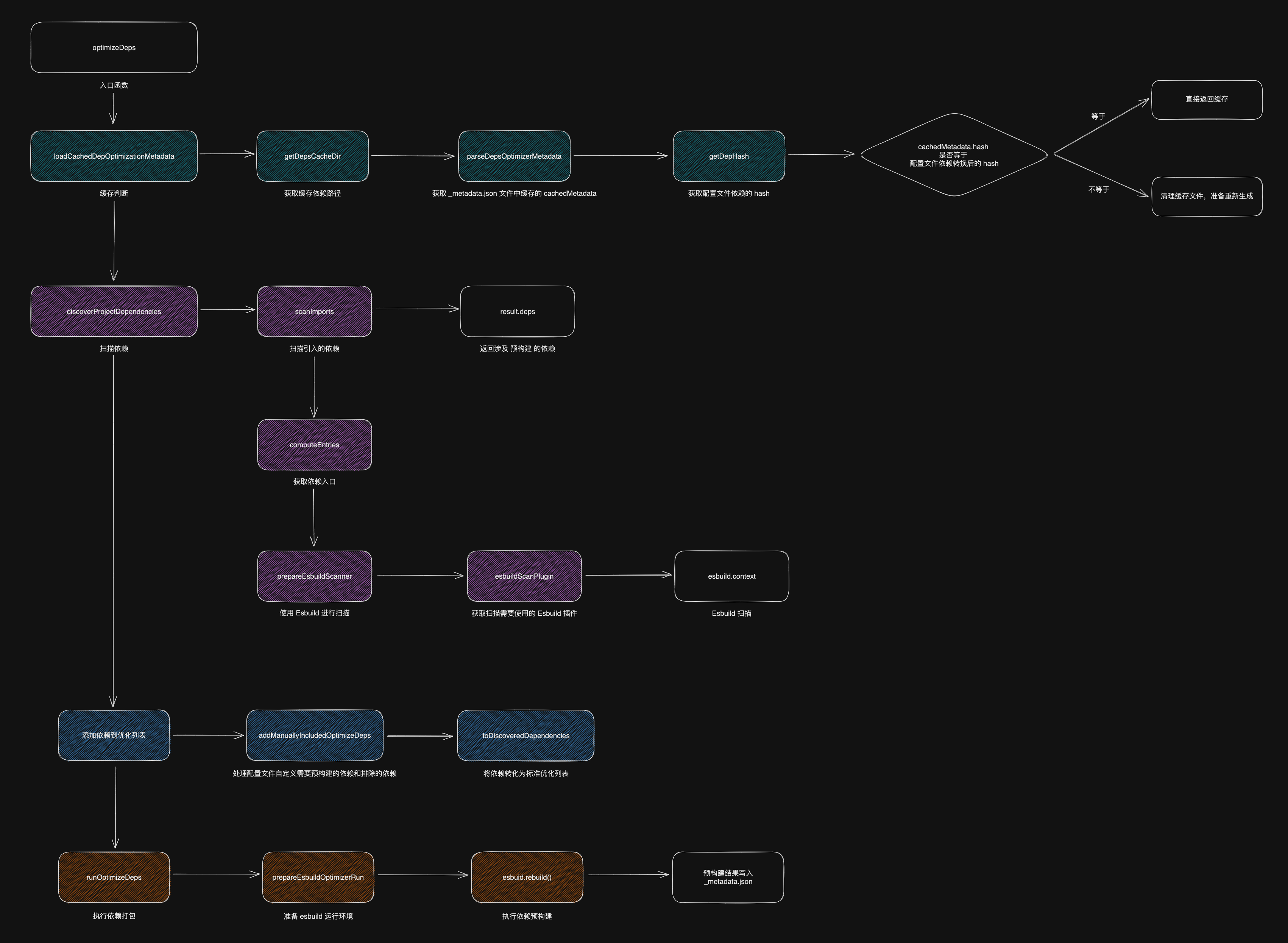
依赖预构建的核心方法是 optimizeDeps ,在 packages/vite/src/node/optimizer/index.ts 文件下,主要有 4 个实现步骤
- 缓存判断,命中缓存直接返回
- 依赖扫描
- 添加依赖到优化列表
- 执行依赖打包
可以看到实现步骤非常清晰,下面就具体分析每一步的实现原理
1export async function optimizeDeps(
2 config: ResolvedConfig,
3 force = config.optimizeDeps.force,
4 asCommand = false
5): Promise<DepOptimizationMetadata> {
6 // 第一步:缓存判断,命中缓存直接返回
7 const cachedMetadata = await loadCachedDepOptimizationMetadata(config, force, asCommand)
8 if (cachedMetadata) {
9 return cachedMetadata
10 }
11
12 // 第二步:依赖扫描
13 const deps = await discoverProjectDependencies(config).result
14
15 // 第三步:添加依赖到优化列表
16 await addManuallyIncludedOptimizeDeps(deps, config)
17
18 const depsInfo = toDiscoveredDependencies(config, deps)
19
20 // 第四步:执行依赖打包
21 const result = await runOptimizeDeps(config, depsInfo).result
22 await result.commit()
23
24 // 返回打包 meta 信息,后续写入 _metadata.json
25 return result.metadata
26}第一步:缓存判断
通过 loadCachedDepOptimizationMetadata 方法判断预构建的缓存 meta 信息是否存在,meta 信息都统一保存在 _meta.json 文件中
缓存判断的实现步骤如下
- 通过
cleanupDepsCacheStaleDirs方法,清理异常退出或执行中断的缓存目录,放在 setTimeout 中异步执行是为了确保加载缓存数据之前,所有残留的缓存目录都已经被清理,保证缓存的一致性和正确性 - 通过
getDepsCacheDir获取缓存依赖路径,也就是 _metadata.json 文件所在的文件路径 - 通过
parseDepsOptimizerMetadata方法解析 meta 数据和依赖预构建缓存 optimized 相关的数据 - 将 meta 数据中的 hash 和
getDepHash依赖获取的 hash 值做对比,如果相同说明命中缓存,直接返回 meta 信息,如果不相同,则移除掉 _metadata.json 文件,准备刷新缓存
1export async function loadCachedDepOptimizationMetadata(
2 config: ResolvedConfig,
3 ssr: boolean,
4 force = config.optimizeDeps.force,
5 asCommand = false
6): Promise<DepOptimizationMetadata | undefined> {
7 if (firstLoadCachedDepOptimizationMetadata) {
8 firstLoadCachedDepOptimizationMetadata = false
9 // 清理异常退出残留的依赖处理目录
10 setTimeout(() => cleanupDepsCacheStaleDirs(config), 0)
11 }
12
13 // 获取缓存依赖路径
14 const depsCacheDir = getDepsCacheDir(config, ssr)
15
16 if (!force) {
17 let cachedMetadata: DepOptimizationMetadata | undefined
18 try {
19 // 获取 _metadata.json 文件所在路径
20 const cachedMetadataPath = path.join(depsCacheDir, '_metadata.json')
21 // 解析 meta 数据
22 cachedMetadata = parseDepsOptimizerMetadata(
23 await fsp.readFile(cachedMetadataPath, 'utf-8'),
24 depsCacheDir
25 )
26 } catch (e) {}
27 // 命中缓存,直接读取缓存 mata 信息
28 if (cachedMetadata && cachedMetadata.hash === getDepHash(config, ssr)) {
29 return cachedMetadata
30 }
31 }
32
33 // 移除文件,准备刷新缓存
34 await fsp.rm(depsCacheDir, { recursive: true, force: true })
35}getDepHash 方法需要展开讲讲,影响缓存 hash 变化的主要有两个方面:lock 文件和配置文件,lock 文件内部记录着依赖的具体信息,如果发生变化自然需要重新构建。另一方面配置文件中的一些参数会影响依赖预构建的方式,如果变化的话同样也需要重新构建
目前 vite 支持的 npm、yarn、pnpm、bun 作为依赖管理工具,bun 是一个更快速的依赖编译和解析工具,这里提供一篇文章作为参考
影响预构建的配置有以下几个配置
- mode:开发 / 生产环境
- root:项目根路径
- resolve:路径解析配置
- buildTarget:最终构建的浏览器兼容目标,比如 es2020,edge88 等等
- assetsInclude:自定义资源类型
- plugins:插件配置
- optimizeDeps:预构建配置
将 lock 文件中的依赖和配置参数合并之后,通过 crypto 的 createHash 方法生成当前依赖和配置的最终 hash
1export function getDepHash(config: ResolvedConfig, ssr: boolean): string {
2 const lockfilePath = lookupFile(config.root, lockfileNames)
3 // 获取 lock 文件内容
4 let content = lockfilePath ? fs.readFileSync(lockfilePath, 'utf-8') : ''
5 if (lockfilePath) {
6 const lockfileName = path.basename(lockfilePath)
7 const { checkPatches } = lockfileFormats.find((f) => f.name === lockfileName)!
8 if (checkPatches) {
9 const fullPath = path.join(path.dirname(lockfilePath), 'patches')
10 const stat = tryStatSync(fullPath)
11 if (stat?.isDirectory()) {
12 content += stat.mtimeMs.toString()
13 }
14 }
15 }
16
17 const optimizeDeps = getDepOptimizationConfig(config, ssr)
18 // 增加会影响依赖预构建的配置
19 content += JSON.stringify(
20 {
21 // 开发 / 生产环境
22 mode: process.env.NODE_ENV || config.mode,
23 // 项目根路径
24 root: config.root,
25 // 路径解析配置
26 resolve: config.resolve,
27 // 最终构建的浏览器兼容目标
28 buildTarget: config.build.target,
29 // 自定义资源类型
30 assetsInclude: config.assetsInclude,
31 // 插件
32 plugins: config.plugins.map((p) => p.name),
33 // 预构建配置
34 optimizeDeps: {
35 include: optimizeDeps?.include,
36 exclude: optimizeDeps?.exclude,
37 esbuildOptions: {
38 ...optimizeDeps?.esbuildOptions,
39 plugins: optimizeDeps?.esbuildOptions?.plugins?.map((p) => p.name),
40 },
41 },
42 },
43 // 特殊正则和函数类型
44 (_, value) => {
45 if (typeof value === 'function' || value instanceof RegExp) {
46 return value.toString()
47 }
48 return value
49 }
50 )
51 // 通过调用 crypto 的 createHash 方法生成哈希
52 return getHash(content)
53}第二步:依赖扫描
在第一步没有命中缓存之后,接下来这一步就要开始扫描有哪些依赖,discoverProjectDependencies 方法比较简单,核心在于通过 scanImports 方法获取依赖扫描的结果
1export function discoverProjectDependencies(config: ResolvedConfig): {
2 cancel: () => Promise<void>
3 result: Promise<Record<string, string>>
4} {
5 // 获取依赖扫描结果
6 const { cancel, result } = scanImports(config)
7
8 return {
9 cancel,
10 result: result.then(({ deps, missing }) => {
11 return deps
12 }),
13 }
14}scanImports 方法主要分为三步
- 通过
computeEntries方法寻找入口 - 通过
prepareEsbuildScanner方法执行依赖扫描,建立 esbuild 上下文 - 执行 esbuild 上下文的
rebuild方法,获取依赖扫描结果
1export function scanImports(config: ResolvedConfig): {
2 cancel: () => Promise<void>
3 result: Promise<{
4 deps: Record<string, string>
5 missing: Record<string, string>
6 }>
7} {
8 const deps: Record<string, string> = {}
9 const missing: Record<string, string> = {}
10 let entries: string[]
11
12 const scanContext = { cancelled: false }
13
14 // 第一步:寻找入口
15 const esbuildContext: Promise<BuildContext | undefined> = computeEntries(config).then(
16 (computedEntries) => {
17 entries = computedEntries
18
19 if (scanContext.cancelled) return
20
21 // 第二步:使用 Esbuild 执行依赖扫描
22 return prepareEsbuildScanner(config, entries, deps, missing, scanContext)
23 }
24 )
25
26 const result = esbuildContext.then((context) => {
27 return context.rebuild().then(() => {
28 return {
29 deps: orderedDependencies(deps),
30 missing,
31 }
32 })
33 })
34
35 return {
36 cancel: async () => {
37 scanContext.cancelled = true
38 return esbuildContext.then((context) => context?.cancel())
39 },
40 result,
41 }
42}第一步 computeEntries 方法用于寻找依赖扫描的入口,按照以下三个顺序寻找
- 首先从 optimizeDeps.entries 中获取入口,支持 glob 语法
- 其次从 build.rollupOptions.input 中获取入口,同时兼容字符串、数组、对象配置方式
- 最后是兜底逻辑,没有配置入口,默认从根目录寻找
1async function computeEntries(config: ResolvedConfig) {
2 let entries: string[] = []
3
4 const explicitEntryPatterns = config.optimizeDeps.entries
5 const buildInput = config.build.rollupOptions?.input
6
7 // 先从 optimizeDeps.entries 中获取入口,支持 glob 语法
8 if (explicitEntryPatterns) {
9 entries = await globEntries(explicitEntryPatterns, config)
10 }
11 // 其次从 build.rollupOptions?.input 中获取入口,兼容数组和对象
12 else if (buildInput) {
13 const resolvePath = (p: string) => path.resolve(config.root, p)
14 if (typeof buildInput === 'string') {
15 entries = [resolvePath(buildInput)]
16 } else if (Array.isArray(buildInput)) {
17 entries = buildInput.map(resolvePath)
18 } else if (isObject(buildInput)) {
19 entries = Object.values(buildInput).map(resolvePath)
20 }
21 } else {
22 // 兜底逻辑,如果没有配置,自动从根目录寻找
23 entries = await globEntries('**/*.html', config)
24 }
25
26 entries = entries.filter((entry) => isScannable(entry) && fs.existsSync(entry))
27
28 return entries
29}第二步 prepareEsbuildScanner 中,通过 esbuildScanPlugin 方法通过定义 esbuild 插件的形式,定义在扫描过程中需要的文件处理,比如
- 支持 对 html、vue、svelte、astro(一种新兴的类 html 语法) 四种后缀的入口文件进行了解析
- 支持对 bare import 场景的处理逻辑
- external 规则处理,排除不需要扫描的依赖
最后利用 esbuild 的 context 方法,将相对路径解析为决定路径的上下文环境,此时的产物是不写入磁盘的,能够节省 IO 的时间
1async function prepareEsbuildScanner(
2 config: ResolvedConfig,
3 entries: string[],
4 deps: Record<string, string>,
5 missing: Record<string, string>,
6 scanContext?: { cancelled: boolean }
7): Promise<BuildContext | undefined> {
8 const container = await createPluginContainer(config)
9
10 if (scanContext?.cancelled) return
11
12 // 扫描需要用到的 Esbuild 插件
13 const plugin = esbuildScanPlugin(config, container, deps, missing, entries)
14
15 const { plugins = [], ...esbuildOptions } = config.optimizeDeps?.esbuildOptions ?? {}
16
17 return await esbuild.context({
18 absWorkingDir: process.cwd(),
19 write: false, // ! 产物不写入磁盘,节省 IO 时间
20 stdin: {
21 contents: entries.map((e) => `import ${JSON.stringify(e)}`).join('\n'),
22 loader: 'js',
23 },
24 bundle: true,
25 format: 'esm',
26 logLevel: 'silent',
27 plugins: [...plugins, plugin],
28 ...esbuildOptions,
29 })
30}最后通过 scanImports 方法扫描依赖的结果 result 作为整个方法的返回,至此第二步扫描依赖就结束了
第三步:添加依赖到优化列表
在扫描了依赖之后,接下来就需要将依赖添加到优化列表
首先会通过 addManuallyIncludedOptimizeDeps 方法处理在配置文件自定义添加到优化列表的依赖,也就是配置文件中的 optimizeDeps 配置,主要实现步骤如下
- 获取配置文件中的 optimizeDeps 配置
- 创建路径解析函数
- 遍历需要添加的依赖数组
- 对依赖的 id 进行标准化处理
- 解析依赖路径,得到依赖入口文件路径
- 将满足条件的依赖放入 deps 对象
1export async function addManuallyIncludedOptimizeDeps(
2 deps: Record<string, string>,
3 config: ResolvedConfig,
4 ssr: boolean,
5 extra: string[] = [],
6 filter?: (id: string) => boolean
7): Promise<void> {
8 const { logger } = config
9 // 获取配置文件中的 optimizeDeps 配置
10 const optimizeDeps = getDepOptimizationConfig(config, ssr)
11 const optimizeDepsInclude = optimizeDeps?.include ?? []
12
13 if (optimizeDepsInclude.length || extra.length) {
14 // 定义需要添加的依赖,排除不需要添加的依赖数组
15 const includes = [...optimizeDepsInclude, ...extra]
16 for (let i = 0; i < includes.length; i++) {
17 const id = includes[i]
18 if (glob.isDynamicPattern(id)) {
19 const globIds = expandGlobIds(id, config)
20 includes.splice(i, 1, ...globIds)
21 i += globIds.length - 1
22 }
23 }
24
25 // 创建路径解析函数
26 const resolve = createOptimizeDepsIncludeResolver(config, ssr)
27
28 // 遍历需要添加的依赖数组
29 for (const id of includes) {
30 // 对依赖的 id 进行标准化处理
31 const normalizedId = normalizeId(id)
32
33 if (!deps[normalizedId] && filter?.(normalizedId) !== false) {
34 // 解析依赖路径,得到依赖入口文件路径
35 const entry = await resolve(id)
36 // 将满足条件的依赖放入 deps 对象
37 if (entry) {
38 if (isOptimizable(entry, optimizeDeps)) {
39 if (!entry.endsWith('?__vite_skip_optimization')) {
40 deps[normalizedId] = entry
41 }
42 }
43 }
44 }
45 }
46 }
47}接下来将 esbuild 扫描的依赖和配置中自定义添加的依赖通过 toDiscoveredDependencies 方法转化一个标准的优化列表
1export function toDiscoveredDependencies(
2 config: ResolvedConfig,
3 deps: Record<string, string>,
4 ssr: boolean,
5 timestamp?: string
6): Record<string, OptimizedDepInfo> {
7 const browserHash = getOptimizedBrowserHash(getDepHash(config, ssr), deps, timestamp)
8
9 const discovered: Record<string, OptimizedDepInfo> = {}
10
11 // 遍历依赖列表,标准化为统一的对象
12 for (const id in deps) {
13 const src = deps[id]
14 discovered[id] = {
15 id,
16 file: getOptimizedDepPath(id, config, ssr),
17 src,
18 browserHash: browserHash,
19 exportsData: extractExportsData(src, config, ssr),
20 }
21 }
22 return discovered
23}至此第三步将依赖添加到优化列表就结束了
第四步:执行依赖打包
接下来就到了最后一步,将上一步获取的依赖优化列表,通过 runOptimizeDeps 方法进行打包
打包过程首先通过 prepareEsbuildOptimizerRun 方法,准备 esbuild 的运行环境,主要步骤会遍历所有依赖,将扁平化依赖记录到 flatIdDeps。再通过 esbuild 的 context 方法,创建上下文,入口就是所有扁平化后的依赖路径
这里的扁平化路径的目的是用作对象的唯一 key,比如 react/jsx-dev-runtime,被重写为react_jsx-dev-runtime
1async function prepareEsbuildOptimizerRun(
2 resolvedConfig: ResolvedConfig,
3 depsInfo: Record<string, OptimizedDepInfo>,
4 ssr: boolean,
5 processingCacheDir: string,
6 optimizerContext: { cancelled: boolean },
7): Promise<{
8 context?: BuildContext
9 idToExports: Record<string, ExportsData>
10}> {
11
12 // 扁平化路径依赖记录
13 const flatIdDeps: Record<string, string> = {}
14
15 // ...
16
17 // 遍历所有依赖,将扁平化路径依赖记录到 flatIdDeps
18 await Promise.all(
19 Object.keys(depsInfo).map(async (id) => {
20 const src = depsInfo[id].src!
21 const exportsData = await(
22 depsInfo[id].exportsData ?? extractExportsData(src, config, ssr),
23 )
24 if (exportsData.jsxLoader && !esbuildOptions.loader?.['.js']) {
25 esbuildOptions.loader = {
26 '.js': 'jsx',
27 ...esbuildOptions.loader,
28 }
29 }
30 // 扁平化路径,`react/jsx-dev-runtime`,被重写为`react_jsx-dev-runtime`
31 const flatId = flattenId(id)
32 flatIdDeps[flatId] = src
33 idToExports[id] = exportsData
34 flatIdToExports[flatId] = exportsData
35 }),
36 )
37
38 // ...
39
40 // 创建 esbuild 上下文,入口为所有扁平化的依赖路径
41 const context = await esbuild.context({
42 absWorkingDir: process.cwd(),
43 entryPoints: Object.keys(flatIdDeps), // 入口
44 bundle: true,
45 platform,
46 define,
47 format: 'esm',
48 target: isBuild ? config.build.target || undefined : ESBUILD_MODULES_TARGET,
49 external,
50 logLevel: 'error',
51 splitting: true,
52 sourcemap: true,
53 outdir: processingCacheDir,
54 ignoreAnnotations: !isBuild,
55 metafile: true,
56 plugins,
57 charset: 'utf8',
58 ...esbuildOptions,
59 supported: {
60 'dynamic-import': true,
61 'import-meta': true,
62 ...esbuildOptions.supported,
63 },
64 })
65 return { context, idToExports }
66}在创建好 esbuild 上下文之后,会调用 rebuild 方法开始执行预构建过程,然后会经历两次遍历过程
- 首先会遍历 depsInfo 依赖信息,将重新构建的依赖信息添加到 metadata 的 optimized 部分
- 然后遍历 metadata 的文件输出路径,将非 js 文件添加到 metadata 的 chunk 部分
1const runResult = preparedRun.then(({ context, idToExports }) => {
2 return context.rebuild().then((result) => {
3 // metadata
4 const meta = result.metafile!
5
6 // 遍历依赖信息,添加到 metadata 的 optimized 部分
7 for (const id in depsInfo) {
8 const output = esbuildOutputFromId(meta.outputs, id, processingCacheDir)
9
10 const { exportsData, ...info } = depsInfo[id]
11 addOptimizedDepInfo(metadata, 'optimized', {
12 ...info,
13 fileHash: getHash(metadata.hash + depsInfo[id].file + JSON.stringify(output.imports)),
14 browserHash: metadata.browserHash,
15 // 判断是否有要转换为 ESM 格式
16 needsInterop: needsInterop(config, ssr, id, idToExports[id], output),
17 })
18 }
19
20 // 遍历 metadata 的输出文件路径
21 for (const o of Object.keys(meta.outputs)) {
22 // 如果不是 js 文件
23 if (!o.match(jsMapExtensionRE)) {
24 const id = path.relative(processingCacheDirOutputPath, o).replace(jsExtensionRE, '')
25 // 根据 id 获取构建依赖的文件路径
26 const file = getOptimizedDepPath(id, resolvedConfig, ssr)
27 // 如果不存在相同的文件,则将输出的文件信息放入 metadata 的 chunk 部分
28 if (!findOptimizedDepInfoInRecord(metadata.optimized, (depInfo) => depInfo.file === file)) {
29 addOptimizedDepInfo(metadata, 'chunks', {
30 id,
31 file,
32 needsInterop: false,
33 browserHash: metadata.browserHash,
34 })
35 }
36 }
37 }
38
39 // ! 注意到此时返回的是 succesfulResult
40 return succesfulResult
41 })
42})在执行完成 rebuild 操作之后,会返回一个 succesfulResult 对象,主要包含三个属性
- metadata:优化后的依赖信息,包括每个依赖的文件路径、导出信息、构建输出文件
- cancel:取消依赖预构建操作
- commit:提交预构建的优化结果,将最后结果写入 _metadata.json 文件
1const succesfulResult: DepOptimizationResult = {
2 metadata,
3 cancel: cleanUp,
4 commit: async () => {
5 committed = true
6 // meta 信息写入 _metadata.json 文件
7 const dataPath = path.join(processingCacheDir, '_metadata.json')
8 fs.writeFileSync(dataPath, stringifyDepsOptimizerMetadata(metadata, depsCacheDir))
9
10 // 将临时文件夹中的优化结果,重命名为全局的依赖缓存文件夹
11 const temporalPath = depsCacheDir + getTempSuffix()
12 const depsCacheDirPresent = fs.existsSync(depsCacheDir)
13 if (isWindows) {
14 if (depsCacheDirPresent) await safeRename(depsCacheDir, temporalPath)
15 await safeRename(processingCacheDir, depsCacheDir)
16 } else {
17 if (depsCacheDirPresent) fs.renameSync(depsCacheDir, temporalPath)
18 fs.renameSync(processingCacheDir, depsCacheDir)
19 }
20
21 // 删除临时路径(旧的全局依赖缓存文件夹),确保临时文件夹的清理工作在后台进行
22 if (depsCacheDirPresent) fsp.rm(temporalPath, { recursive: true, force: true })
23 },
24}最后会执行 commit 方法,完成依赖预构建的全部过程
1// 第四步:执行依赖打包
2const result = await runOptimizeDeps(config, depsInfo).result
3
4await result.commit()
5
6// 返回打包 meta 信息,后续写入 _metadata.json
7return result.metadata总结
最后总结一下 vite 依赖预构建的实现步骤
- 缓存判断:根据文件生成的 hash 和 _metadata.json 中的记录的缓存文件 hash 进行对比,如果相同说明命中缓存
- 依赖扫描:获取扫描入口,使用 esbuild 进行扫描
- 添加依赖到优化列表:将配置文件自定义的优化依赖和扫描依赖结果添加到优化列表
- 依赖打包:使用 esbuild 进行依赖打包,产物写入 _metadata.json 文件